A 2D graphics engine using algorithms based on vectors and written in C# using System.Drawing and Windows Forms. I am reinventing the wheel, so hopefully me developing the thing will be as interesting as a story as it is a journey for me. Who knows, I might also share some programming tricks of the trade.





Articles
Here is an easy way to learn something - find a project, which requires the implementing of the thing in question. And this project is one example.
Using Analytical Geometry (AG), I was able to develop some fast algorithms for developing a simple 2D engine. Now, I could have used almost no maths to build the engine, but that would have made the engine extremely limited in its functionality. Using AG I can achieve a lot of flexibility and potential power.
Github.com The two .cs files, that are for the WinForms - I refer to them as the "game's code". The rest of the files should be able to be compiled into a .dll and then used in other projects, but I still can't get the thing to work properly.
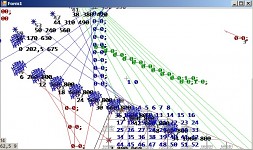
For double buffering in WinForms just use a picture box: draw the image on a separate bitmap and then set the form's image to be the bitmap. It should work better than a canvas.
So, what does the engine do?
- Determine what is visible by the screen
- Handle all possible positions for the screen
- Calculate where things should be drawn on the screen
- Basic algorithms for calculating when points, lines and polygons are visible
And how does it do all that?
A few things before the explanations start:
- Plane - where all objects are spread
- Section - a part of a plane
- Basis - the two vectors, based on which the coordinates of a point work
- The plane's basis has coordinates according to the screen's basis, the screen's basis vectors are always X(1,0) and Y(0,1)
You could ask "What is there so much into determining what is there to draw and what not?". The problem here is not what is visible, but what is not. We are not dealing with just a few things, which can be seen by the "camera", but potentially an infinite amount of objects. If we are to leave all of that stuff to be scanned through, regardless if it is in the screen or not, we can get potentially infinite calculating time. And we don't want that. To go around this problem, the engine divides the plane in square sections and when adding objects it memorizes which sections contain which objects. From here it is pretty simple: see which sections are visible by the screen and then calculate if the contained objects are visible by the screen. The size of a section is determined by the size of the screen and the maximum zoom-out that can be set (I will write about that later).
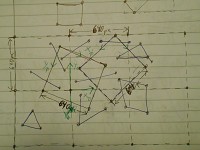
The engine is built in a way, which allows the screen not only to move up, down, left and right, but to also be able to rotate and zoom-in and out. Here things get a bit tricky, because the camera can see more or less things while zooming and then rotated when rotating. The engine calculates where the screen would project on the plane, and based on that result it determines which sections are visible and then which objects. This is done by constant switches between the bases of the screen and plane.
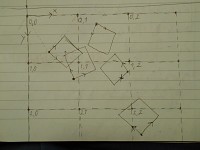
Speaking of constant switches between bases, this the main thing that requires to divide the plane into sections. The fact, that the screen can be rotated and zoomed, requires objects' coordinates to be constantly switched between bases. Despite having fast algorithms for that, they are still calculations requiring time. Once the engine finds which sections are visible, all contained objects' coordinates are switched to the screen's basis and then calculated what is visible.
Probably the hardest part is to determine in which section an object lies. You can have a simple point, but you can have a point with an image, a line, a polygon, each requiring their own algorithms. You must understand, that a computer does not have the "strategic" view humans do, but only sees numbers. Practically, that is the same as trying to answer the same problems, but this time you are down there, trying to navigate. A point's image can spread on more than one sections, a line's end can stay on a section border, which conflicts with a few other algorithms and a polygon can be filled, and to have a few section inside. I have gone into detail about the algorithms in the code I posted, but I am planning to explain them here as well.
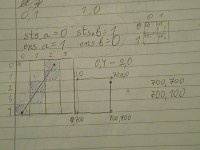

Yes, the whole process before the actual drawing is a kinda long and tricky, but it allows the engine to be able to handle a lot of stuff on the plane, without increasing the weight on the CPU too much. A similar thing happens in modern 3D engines (or at least in BigWorld): there is an algorithm, that detects what is directly visible ignoring the rest - this is on its own requires calculations, but it is much faster than scanning everything if it is visible or not.
Implemented stuff:
- Basis algorithms for calculating coordinates
- Movement, rotation and zooming of the camera.
- Algorithms for the basic entities dot, line and polygon
- Entities can be set with methods
- Entities' occupied sections are being calculated dynamically
- Diversions in the basis vectors for visual effects
- Plane can be set with additional methods
- To set an entity with a drawing algorithm, the class must implement a certain interface
Implemented stuff, that may need fixing, more work or removal:
FPS system (but it is in the game's code) - I really don't know how the FPS change depending onwhere a cycle's time is being tracked, and I can't increase the FPS over a certain point- Getting a more accurate frame rate calculation - all entities work in separate threads, so counting the time is not guaranteed accurate
Setting the plane to do additional stuff on each game cycle
Work to do:
Implement the plane's basis' vectors to be set with diversion to allow fancy visual effectsImprove the code's interface - will require testing to do that- Fix bugs. But first - figure out why they happen.
Feedback from testing is appreciated! Thank you for reading.
Post a comment
Mod SDK & Community
Built a game for Vector Based Lines Engine (2D) and want to support mods? Try mod.io, a cross-platform mod SDK created by ModDB which makes it easy to get a mod community up and running in-game. Currently seeking games to integrate and promote

X
Tags
Embed Buttons
Link to Vector Based Lines Engine (2D) by selecting a button and using the embed code provided more...


You may also like




