Bright Engine is a Light-Weight C++ Rendering platform aimed towards, Real-time rendering for both Video Games and Cinematic Animations. It is still very early in its life-cycle, but has been designed with scalability in mind allowing for any form of project to be created. From a first person shooter to a Massively multi-player online game.
The mission is to create a robust development tool that acts as a viable alternative to other mainstream products by providing complete control and customisability, allowing the Engine to suit any project while still remaining simple and efficient to use. While the Editor does the heavy lifting, you can go into the heart of your project and edit the source code of the executable to achieve anything you want (including adding your own custom or other 3rd party libraries).
Bright Engine has undergone and still continues to be rigorously tested by a growing community of dedicated game developers who have ensured maximum stability with each new update.
If you are interested in Bright Engine and want to snag up a free copy you are welcome to join the Discord community to ask questions or follow our progress on Trello to get real time development progress updates!






Articles

Continuing on from the upgrades introduced in R2, the engineering team have been redesigning major parts of Bright Engine’s rendering system. Plenty of redundant code has been removed, and significant chunks of the CPU-sided code have been rewritten to be both more memory efficient and reduce GPU idling.


A Huge Thank you to our Patrons! Your contributions make Bright Engine Possible!
Zeppot • Daniel Burkhart • Massum Zaidi • Mark Makarainen
Improvement: Codebase Architecture
Bright Engine is begin designed under the mantra of keeping everything lightweight. We’re constantly removing dependencies on old redundant legacy code. The goal is to avoid falling into the trap where in the long-term, our technology builds up a massive technical debt that so many other engines suffer from.
When this project started, we encapsulated all of the codebase into two executables: the World Editor and the Game Client. In the early days, this worked rather well. But as the feature set and capabilities of Bright Engine expanded, this approach started to create problems.
The first was much longer build times for our programmers. The more code an application has, the longer it takes for a compiler to do its job. And when we’re having to wait 30-40 seconds between testing each change in the code base, a lot of time ends up being wasted.
The second major issue is code duplication. In the past, all the object classes, render functions, and so forth were duplicated in the Editor and Game Client. And that was actually creating a lot of unnecessary work. After all, if we changed something in the Editor, then we’d have to make the same change in the Game Client, which became tedious, to say the least.
Towards the end of 2021, we started getting fed up with these annoyances and began migrating the shared code between the Editor and Game Client into Dynamic Link Libraries (DLLs). In oversimplified terms, by putting the code into these libraries, we now only have to change the code once, and it will automatically update both the Editor and Game Client, making the project far more manageable.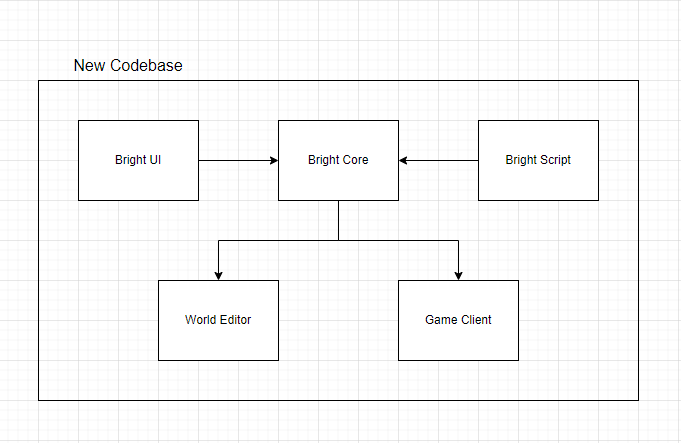
Sadly this process isn’t just a simple case of flicking a switch. Moving code from one project into another creates a tonne of errors that, while easy to fix, take a long time.
In Version 2022 R3, this migration process is now 80% complete. We’ve now finished moving over all the object classes, the Universal Resource Management system introduced in Version 2022 R1 has also been shifted, and the entire render pipeline is now relocated as well.
This helped eliminate around 15,000 lines of duplicated code across the World Editor and Game Client. But we weren’t just copying existing code. We actually took this as an opportunity to clean out old systems while further optimising Object Class data structure to fit better in the CPU cache.
Approximately 2,000 lines of code were removed with no loss in functionality, and 14 shader programmes were removed. And we were also able to flag other areas for further improvements in future updates.
Overall this code migration has drastically improved our ability to maintain a healthy code base, reduced building times, and with less dead weight, the CPU is able to do its tasks faster. As such, CPU rendering time per frame dropped from an average of 6.4ms to 5.5ms. Meanwhile, in the Game Client, which doesn’t have all the overhead from development tools, the CPU render time is down from 4.5ms to 3.2ms.
In terms of Frames per Second, this has made a significant difference on weaker machines. However, it’s worth pointing out that this is still not good enough. In the long term, we’re aiming to get CPU render times under 1.5 ms. Still, it’s encouraging to see things move in the right direction.
Improvement: Terrain Rendering
Terrain rendering has probably gone through more iterations than any other system in the engine so far. Yet as our knowledge expands, so does the system.
In Version 0.1.8c, we introduced a CDLOD rendering method to handle dynamic geometry detail. However, its implementation, while functional, created quite a few issues, including an overly aggressive occlusion query for nodes near the camera. This resulted in gaps forming at certain angles and weird depth testing issues.
But the biggest problem was CPU performance. Since Bright Engine breaks up terrain into individual 128 x 128-meter chunks, a node draw had to be generated for each chunk in the scene, which, when dealing with a larger environment, created massive bottlenecks in the render pipeline.
Consequently, in a relatively small scene of 384 x 384-meter terrain, frames per second barely managed to stay above 8. Needless to say, that’s terrible.
The implementation had a lot of geometry data stored in vertex buffers were being generated and sent to the GPU despite most of it going unused. In other words, extra work was being done by the CPU for no reason. This has now been fixed, with the CDLOD functions disabled until a more efficient approach can be designed.
After fixing the issues with data management, the FPS of the 384 x 384-meter terrain stress test jumped from an average of 8 to an average of 38. This massive jump in performance perfectly highlights how bad things were before.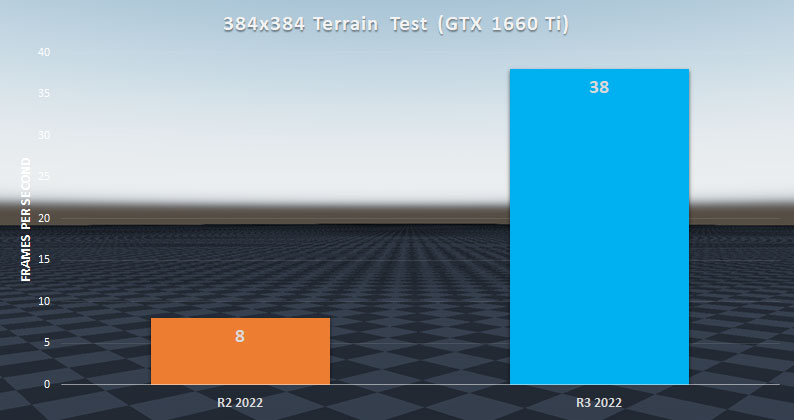
The performance improvements to terrain rendering don’t end here, though. Another major bottleneck in the terrain rendering system is the binding of textures from terrain layers.
Each terrain layer has 9 texture maps (Albedo, Alpha, Normal, Height, Metalness, Roughness, Reflectance, Emission Color, Emission Mask). Most GPUs can only bind 16-32 textures per shader programme per draw call at one time. And that’s obviously not enough to render a whole lump of terrain.
To get past this hardware limitation, Bright Engine automatically channel packs these nine textures into four. And then, texture packs these four into four texture arrays. By storing texture data as an array, multiple textures can be sent to the GPU while only using one texture slot in a shader. 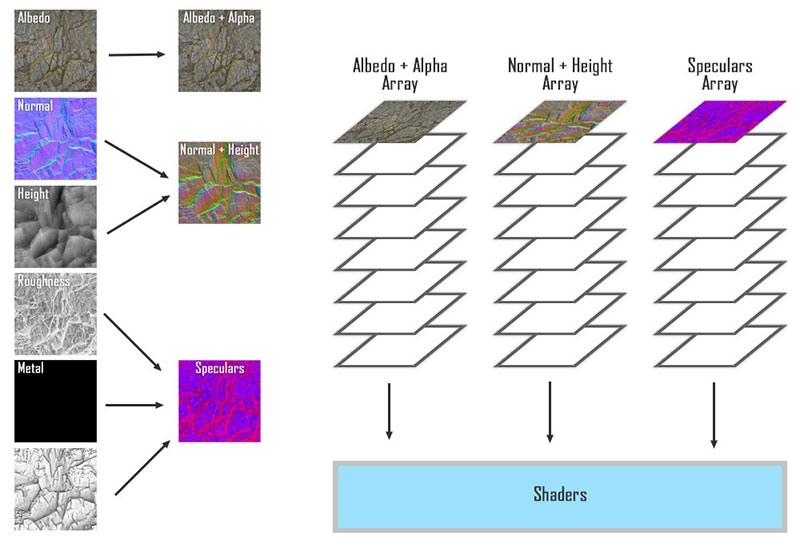
This bypasses the texture count limit. However, these texture arrays still need to be bound to the shader. And depending on how many textures are inside, this binding process can take a lot of time, relatively speaking.
In earlier versions of Bright Engine, the renderer loops through each chunk to bind their shader uniforms and their texture arrays before drawing the geometry.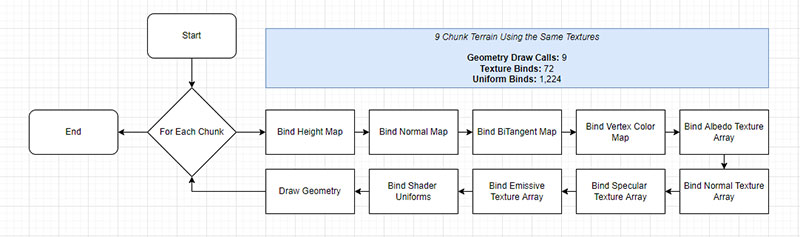
A 384 x 384-meter terrain scene has 9 chunks, each with 4 channel-packed texture arrays and 12 shader uniform variables per terrain layer. This equates to 36 expensive texture binding operations in a single frame just for the terrain.
So, to fix this, we redesigned the way texture layers are handled. Instead of assigning textures directly to terrain, we built a brand new Terrain Material Set system.
Users now create their texture layers inside a Terrain Material Set. Then for each chunk in the scene, the user specifies which material set should be used. Bright Engine then builds a render stack of the terrain chunks in the order of the assigned Terrain Material Sets.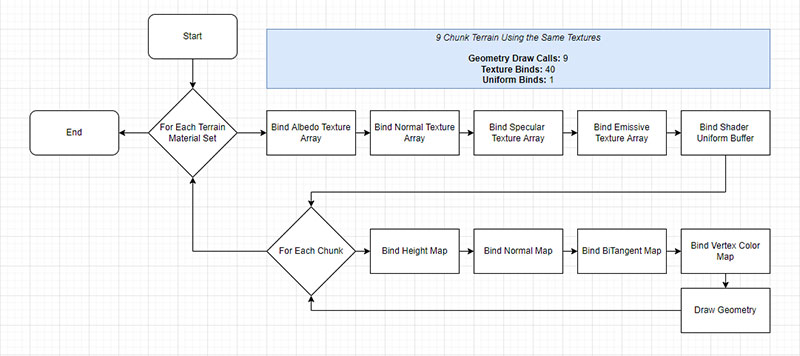
This approach has two major advantages.
The first is a user-friendly upgrade. If a texture layer of a Terrain Material Set is edited, all chunks using that Set are automatically updated. Before, a user would have to update each individual chunk one by one in a time-consuming process that was incredibly annoying, especially when working with larger scenes.
The second is by rendering per material set, the texture binding process only needs to be performed once per group of chunks using that set.
In the 384 x 384-meter test scene, each chunk had the same textures, which were put inside a Terrain Material Set that was assigned to each chunk. The end result is only 4 texture binds for terrain layer textures instead of 36 for the exact same result. Including the other auxiliary maps, that brings the total down from 72 to 40 - a 44% reduction.
But that still leaves us with the issue of the shader uniforms. As a reminder, shader uniforms contain the values of various settings that are applied to each texture layer, such as normal map strength, height map strength, etc. These are sent as an array from the CPU to the GPU during the rendering process, but it requires a whole bunch of Uniform Binding operations to be executed.
For a single Terrain Material Set, there are 8 texture layers, each with 17 uniform variables resulting in 136 Uniform Binding operations per chunk in the render loop. This is far from ideal, but in a single chunk scene, chances are the performance impact will be negligible. However, the performance drain becomes exponentially more apparent for each additional chunk added to the scene.
In Bright Engine Version R2, that meant the 9-chunk test environment had to perform 1,224 Uniform Binding commands had to be executed just to draw the terrain! No good.
To fix this, we expanded our knowledge of Uniform Buffers from Version R2 and applied it to terrain rendering. Instead of binding the uniforms one by one, we packaged up all the variables into a buffer and then bound the buffer, reducing the 136 Uniform Binding commands per chunk down to 1 per Terrain Material Set.
By fixing these performance bottlenecks, terrain render speeds went from 38 fps to 199!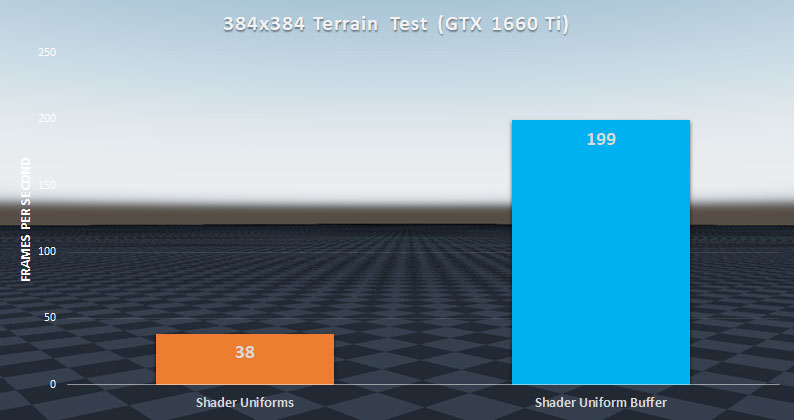
However, this is only the tip of the iceberg. 40 texture binds is still too much. Fortunately, we’ve already mapped out plans to bring this figure down even further. By packing the other auxiliary maps into their own texture arrays and introducing some instanced rendering techniques, we’re able to bring both the number of texture binds, and geometry draw calls down to 9 and 1, respectively, per Terrain Material Set. Sadly we didn’t have time to implement this optimisation this time around, but it will be included in the next update.
While testing the performance of terrain and inspecting the impact of adding additional chunks, we quickly discovered how infuriatingly slow the process took to add large landscapes to a scene without using a height map. So we made a small detour and added a new tool for users.
Terrain chunks can still be added individually. But for those seeking to quickly generate large-scale landscapes, we’ve added a new option that lets users specify the dimensions of the landscape in terms of chunks along with an offset in position. Suddenly making a 512 x 512-meter landscape takes seconds instead of minutes.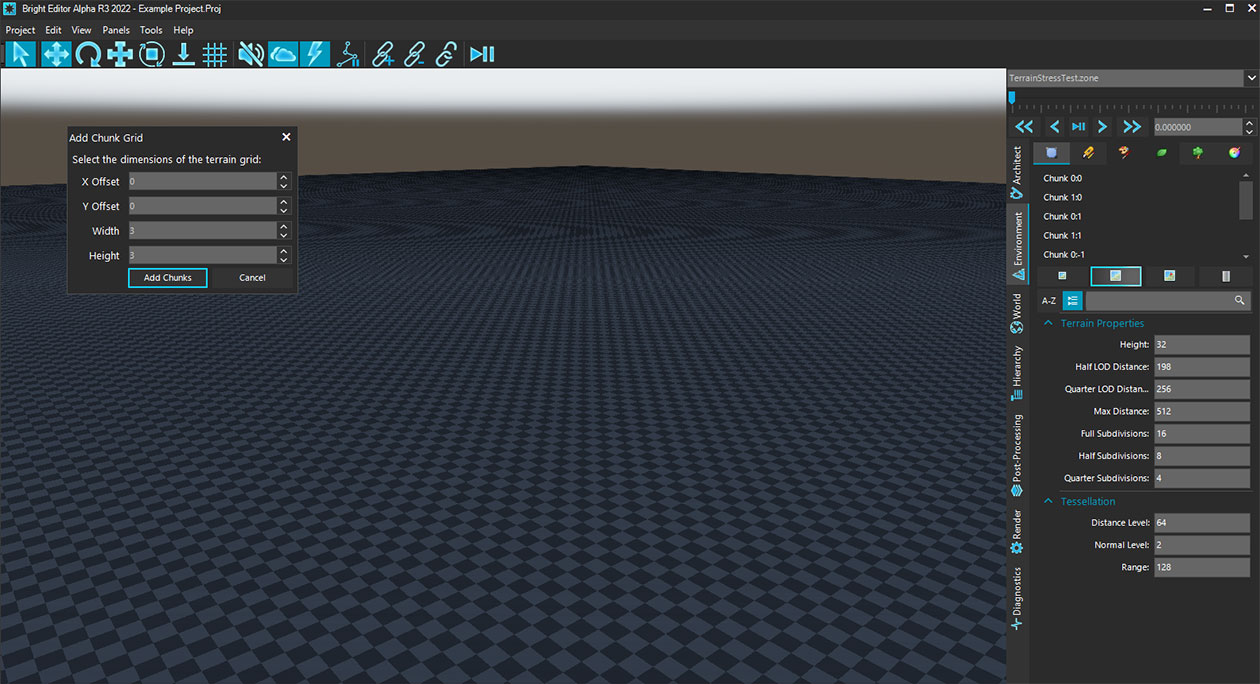
Lastly, we fixed a visual bug with terrain UVs where values were being generated in vertex space rather than pixel space causing low accuracy texture mapping at distances.
Improvement: Lighting Rendering
In Version R2, we introduced Uniform Buffers to handle all the shader uniforms of Directional, Point, and Spot lights. This has now been extended to Area lights eliminating more unnecessary Uniform Binding commands per frame.
For scenes with only a couple of area lights, the performance difference is negligible. But for scenes utilising the maximum capacity of 16 at a one time, the shift towards Uniform Buffers has made a significant difference.
Additionally, the data layout of Uniform Buffer structures had some misalignment issues with the std140 OpenGL data layout. These have now been fixed, eliminating some strange behaviours in scenes with more than eight light sources of the same type.
Upon feedback from the community, there was some confusion surrounding the shadow settings of Area Lights. In the current version of Bright Engine, area light shadows are currently not supported. Therefore, the engine will now hide the shadow settings of an area light to avoid confusion. Support for area light shadows will be added in a future update.
Improvement: Skybox, Clouds, and Fog Rendering
We’ve made some significant under-the-hood changes to how Bright Engine handles Skyboxes, Clouds, and Fog.
Starting with skyboxes, Bright Engine originally sent the environment, pre-filter, and irradiance maps to the Skybox and Deffered PBR shaders. However, this approach, while functional, created a lot of unnecessary texture binding operations followed by repeated value blending in shaders.
Therefore, we’ve added an additional step in the render loop that combines the various environment, pre-filter, and irradiance maps into one. This means skybox textures only need to be bound once per shader, giving a slight boost to CPU and GPU rendering speeds.
Additionally, the blended values when transitioning between skybox, cloud, and fog layers were originally calculated on the GPU. However, given the results don’t change in a single frame, we’ve now moved these calculations to the CPU, which then sends the results to the GPU.
Why? Because now a blended value is only calculated once per frame instead of once per vertex per frame. Needless to say, that’s significantly less work!
Beyond performance optimisations, we also added a few requested features.
Users can now show/hide cloud layers in the editor.
We also added some new settings for Fog layers that enable colour blending with the skybox, giving a more smooth transition at the edge of the maximum render distance.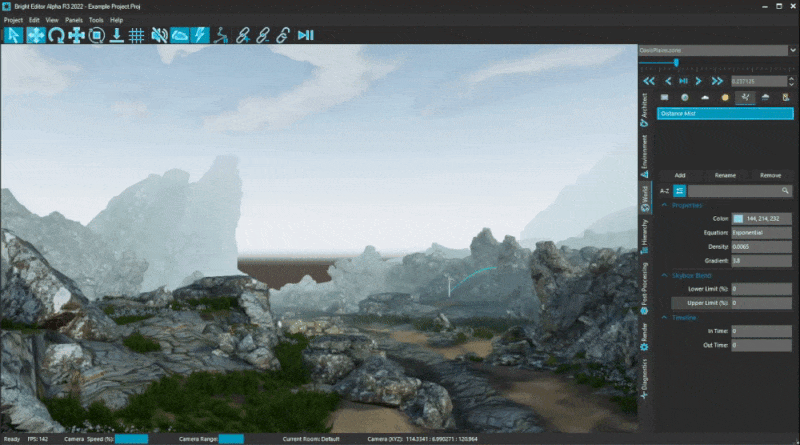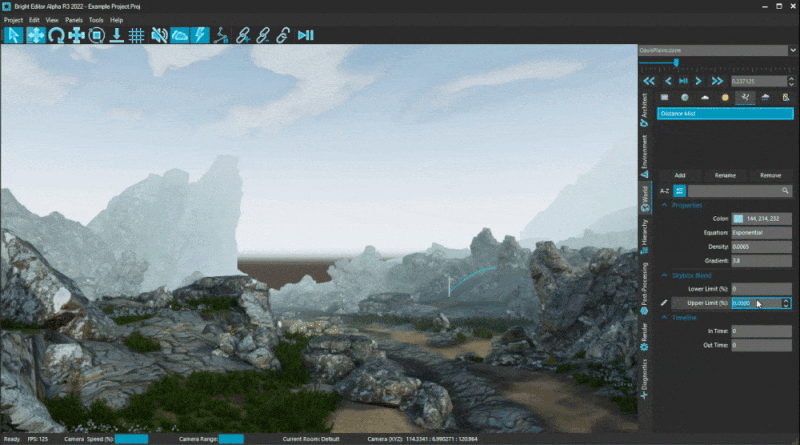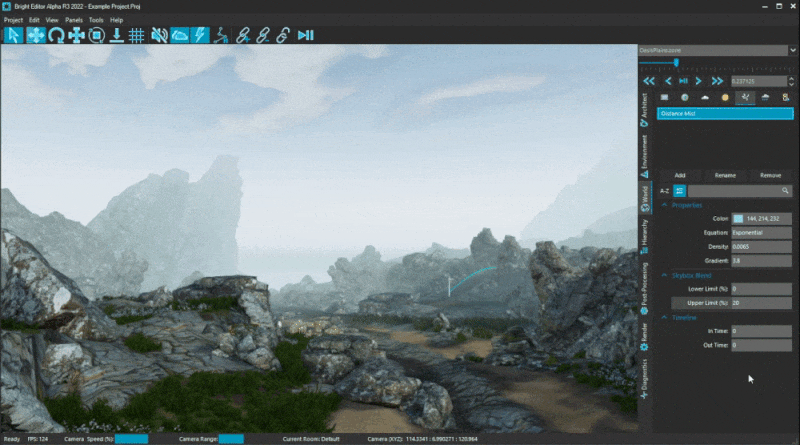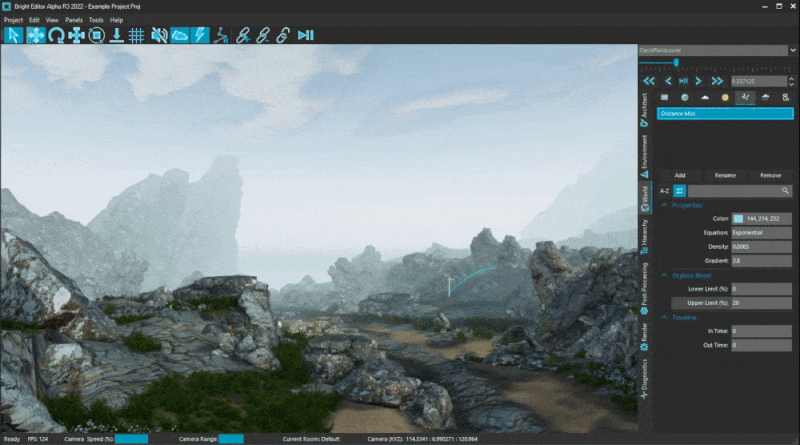
The Results
Combining all these optimisations, the Demo Plains test scene is now hitting an average FPS of 142 versus the 50 fps achieved in R2 2022.
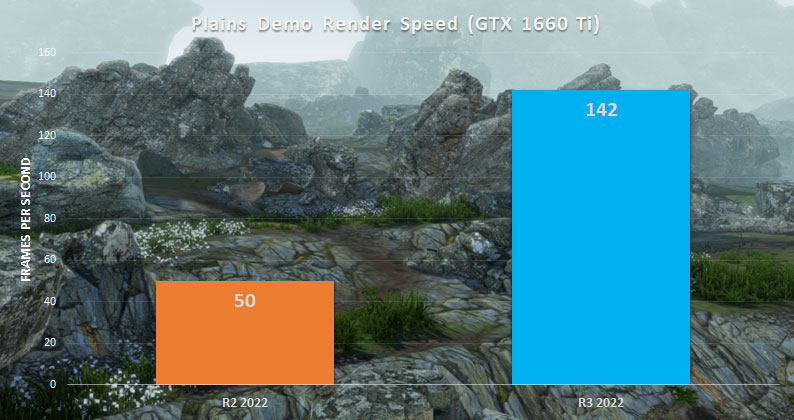
This is obviously a massive difference, but we’re still just getting started on further optimising the rendering process. The engine still needs a lot of work before it can support the long-term goal of massive open worlds. But we are getting closer.
Bug Fixes
[World Editor]
- Fixed bug where temporary data during material loading wasn't cleared correctly [memory leak]
- Fixed bug where deleting a room placement caused a crash when a new room placement was added later
- Fixed bug where zones with no sun would sometimes crash
- Fixed bug where manually setting the scale values of a model instead of using the 3D Gimbal didn't update in the viewport
- Fixed bug where the default room wasn't being selected automatically, creating multiple crash points
- Fixed bug where the BRDF Look Up table was being regenerated every time a zone was loaded (performance)
- Fixed bug where the Out Time setting for skyboxes was incorrectly being labelled
- Fixed bug where opening the drop-down menu when selecting a skybox cubemap but then not selecting an item would cause a crash
- Fixed bug where the model brush UI list wasn't being cleared when switching between zones
- Fixed bug where certain light settings weren't being applied correctly
- Fixed bug where changing terrain settings without a chunk selected had no effect
- Fixed bug where toggling fog on and off sometimes didn't work
- Fixed bug where swapping to a different zone with a room placement selected would cause a crash
- Fixed bug where selecting a room, swapping to a new zone, and then entering the World tab would cause a crash (this was a weird one)
- Fixed bug where a target assigned to a waypoint path would cause a crash the next time the zone was loaded
- Fixed bug where creating a room placement would cause a crash after deselecting it
- Fixed bug where each zone's asset brush file wasn't correctly being generated
What's Next?
With an FPS of 142, the Demo Plains test scene is no longer a suitable stress-test environment for future performance comparisons. Therefore, we’ve begun planning and will soon be assembling a brand new demo scene which will be roughly five times larger and serve as a much better benchmark moving forward, utilising far more features of the engine, pushing it even further to the limit.
Building the environment isn’t going to happen overnight or in a single update. But using Bright Engine’s tools to build another complete scene gives us the ability to discover usability issues or new opportunities to accelerate the world-building process.
Scripting is also going to receive some much-needed love to fix up all the kinks in its current implementation, and we’ve already begun researching water rendering.
Furthermore, thanks to some amazing insight from the engine developers of Horizon: Zero Dawn, we’ve also got a total overhaul of the weather, foliage, and wind simulation systems in the works, along with the re-introduction of model LODs.
There’s a lot of exciting stuff in the pipeline for the next couple of updates as we prepare to move Bright Engine out of Alpha and into Early Beta. Stay tuned for what comes next!

Bright Engine 2022 R2 Patch Notes! - Performance & Optimisation
NewsIt’s been two months of an architectural overhaul for the Bright Engine render pipeline. The engineering team have been making substantial changes to...
Bright Engine 2022 R1 Patch Notes! - UI & Resource Management
News 2 commentsAfter months of programming, the time has come again to show off what our engineering team has been up to. A lot of under the hood architecture has been...

Bright Engine v0.1.8c Patch Notes! - Open Worlds Part 1
NewsThis update is the first of several to bring Open-World support to Bright Engine starting with various performance improvements, as well as the long-awaited...

Bright Engine v0.1.8b Patch Notes! - Terrain Tessellation
NewsThis update aimed to make substantial improvements to the engine’s existing systems, namely landscapes. The entire terrain system and dynamic foliage...
Post a comment
Mod SDK & Community
Built a game for Bright Engine and want to support mods? Try mod.io, a cross-platform mod SDK created by ModDB which makes it easy to get a mod community up and running in-game. Currently seeking games to integrate and promote

X
Tags
Embed Buttons
Link to Bright Engine by selecting a button and using the embed code provided more...



You may also like

Unreal Engine 4
Commercial
Kapow Systems 3D
Proprietary

Source
Commercial

Bright Engine
Commercial

WOLF RPG Editor
GPL

Unreal Development Kit
Commercial
Looks cool, I'm going to join the Alpha. Give it a spin.
Wow thanks! Hope you like what we've got so far! :D
Looks sick. Might use this.
Awesome! :D I see you have already joined the Discord Server, Welcome to the Community!
Very promising, I love the concept. Keeping a tab on it.
Thanks! We'll continue to work hard and post plenty of updates as we do! :)
HI! Everything looks really cool! Just wanna ask, what's unique about this engine than the others? Unity is easy to use and Unreal... well, beautiful graphic. Yours?
Is it sounds rude? If it is, SORRY!!
No need to apologise its a perfectly valid question!
Unity and Unreal are undoubtedly powerful tools but have become very unfocused by trying to attract every project possible (meaning that extra steps have been forced into the pipeline in order to account for everyone using it). Our goal is to try make the process of achieving desired effects and systems more streamlined and simple without forfeiting capability and power to the user. For example setting up a day and night cycle in Unity or Unreal requires messing around with scripting (or nodes) and can cause confusion as you try to make the system more complex. In Bright with a few clicks in the Editor you have Skybox blending, lighting transitions, fog, sun/moons & weather all ready and done for you. And if the Engine hasn't got a setting you want to adjust, there is nothing from stopping from using custom shaders to achieve the desired effect until its implemented into the engine by the dev team. So far we think we're on the right track and a few of our testers agree, though there is a lot of work left to go.
Aside from all that, we simply wanted to create a tool for our own projects in the future and share it with our growing community who have been helping from day one to improve the engine! :)
Thanks for the detailed explanation! As I don't really like to develop games in 3D, I just keep looking at your engine. Sorry! Although, if you do start to focus on 2D, do tell us(The community...)!
Well technically speaking a 2D game is actually in 3D space with an orthographic camera system. We're currently focused on developing all the 3D side of things but once we introduce a comprehensive camera system for in Editor Game Testing, it really won't be difficult to add the 2D support with the way everything has bee set up so far! :)