Prologue - Korolyov, we have a problem
Back in 2009 when we've decided to set up our first server there was a negligible amount of suspicion that a sneaky cowardly attack on an innocent hardware may occur in the near future. As it turned out, the near future happened to be a period of no lo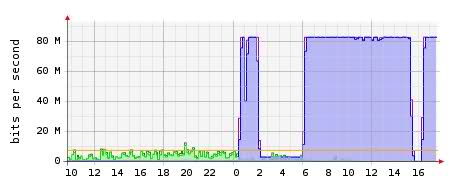 nger than three years. First signs of quirkiness have been detected on Wednesday, i.e. four days ago. In just a few minutes the regular amount of traffic multiplied itself, as you can see on the graph provided. The server was shut down by our host soon shortly thereafter, as response to the insane data transfers and packet bombardment. We have reached the well-known "lock-down" procedure and were waiting to get our remote hands on the server in order to bring it up online.
nger than three years. First signs of quirkiness have been detected on Wednesday, i.e. four days ago. In just a few minutes the regular amount of traffic multiplied itself, as you can see on the graph provided. The server was shut down by our host soon shortly thereafter, as response to the insane data transfers and packet bombardment. We have reached the well-known "lock-down" procedure and were waiting to get our remote hands on the server in order to bring it up online.
Chapter one - Can it really be managed remotely in an effective manner?
 One way or another, we were patiently waiting for the lock-down to end. Just when the server was supposed to be up and running again, it wasn't responding. It could have been pinged most of the time and the the low-level host control panels were responding, but booting up the old chap with primary OS was impossible. The technical support was (probably) doing their best to answer to our requests, but the communication was tedious, usually taking too long or resulting in additional waiting intervals. In other words, remote management proved to be quite difficult, which we were counting on, since we're talking about one of the cheapest hosting solutions among those offered by our host.
One way or another, we were patiently waiting for the lock-down to end. Just when the server was supposed to be up and running again, it wasn't responding. It could have been pinged most of the time and the the low-level host control panels were responding, but booting up the old chap with primary OS was impossible. The technical support was (probably) doing their best to answer to our requests, but the communication was tedious, usually taking too long or resulting in additional waiting intervals. In other words, remote management proved to be quite difficult, which we were counting on, since we're talking about one of the cheapest hosting solutions among those offered by our host.
Chapter two - Where are my data?
For one reason or another, there have been some posts on certain community boards about the recent issues with the 2238 server indicating that critical server data have been lost. I, for one, couldn't think of any way or possibility how anyone outside the Rotators development circle would happen to know those "facts" even before we started to check the data integrity. It would be in common interest to restrain from such comments for the time being and to stick to the official announcements and facts. You can follow us on our blog and get the latest information there, since it has been updated regularly.
Chapter three - Solution
I'd dare to say that this is not a case without solution and we have been considering several options for quite a time already. Long story short - one of the most intriguing ideas right now is to move to another host, i.e. to find a better offer for beans, getting... ehmmm... more (and better) beans in the process. Currently, our critical control point proved to be the above mentioned server management, which provides us with next to none flexibility when it comes to keeping the server up n' running. As all of us already know, proper server management is necessity for projects like 2238, no more, no less. According to some unofficial feedback, there's a good portion of players and the community interested in backing up such kind of "exodus", which is a good sign and a wind in the back for meeting the final decision. Anyway, we would like to use this opportunity to thank everyone for supporting us during all good and hard times we've been through together.
Epilogue - Hiigara
Will we ever get there? Who knows, but we're certainly on our way. The Mothership is in a critical state with hyperdrives damaged and rendered useless in this nebula, but we can't give up now. No, not at this point. Fleet Command: Stand by for Command Line testing…



Well, at least now you can figure out where the weaknesses in defenses are, right?
Well, yes, kind of. How to put it correctly? Right now the emphasis is not put on preventing such attack (complete prevention and ultimate defence are impossible to achieve), but rather on the ability to get the server back to normal condition asap. I hope the article will be interesting for anyone planning to run a server for a non-profit free-of-charge MMO.